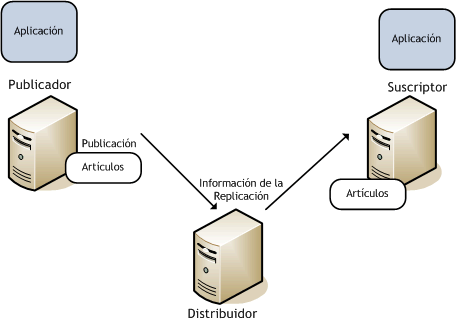
En esta entrada vamos a ahondar en uno de los elementos más importantes dentro de la arquitectura de los sistemas PACS, la Lista de Trabajo. Su función principal es la de unir el sistema de información radiológico con el sistema de almacenamiento de imágenes, posibilitando la correcta asociación entre paciente e imagen.
Los apartados que trataremos son:
Visión Global de la Funcionalidad
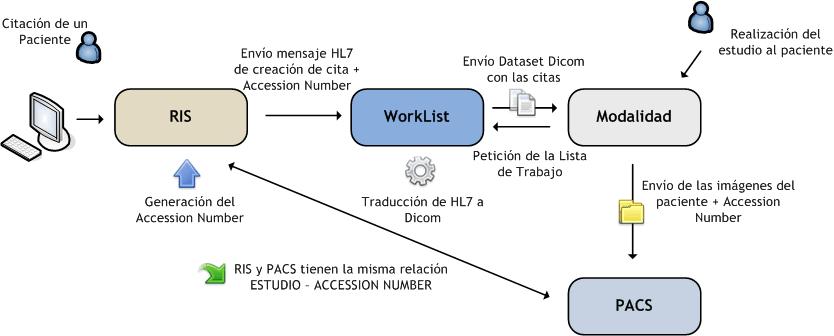
Como hemos comentado, la función principal de la Lista de Trabajo es conseguir que las imágenes generadas en las modalidades se asocien de forma correcta al paciente del que son. Desde el punto de vista de los técnicos de rayos, la lista de trabajo permite que en las consolas de sus modalidades aparezcan aquellos pacientes citados para el día de forma que ellos los puedan seleccionar y hacerles el estudio correspondientes. Desde el punto de vista informático, el proceso es ligeramente más complejo. En el siguiente diagrama vemos cuál es el flujo básico de la información:

El proceso completo es el siguiente:
Los apartados que trataremos son:
- Visión Global de la Funcionalidad
- Utilidad de la WorkList
- Posibles Arquitectura de la Lista de Trabajo
- La Mensajería MPPS y la Lista de Trabajo
Visión Global de la Funcionalidad
Como hemos comentado, la función principal de la Lista de Trabajo es conseguir que las imágenes generadas en las modalidades se asocien de forma correcta al paciente del que son. Desde el punto de vista de los técnicos de rayos, la lista de trabajo permite que en las consolas de sus modalidades aparezcan aquellos pacientes citados para el día de forma que ellos los puedan seleccionar y hacerles el estudio correspondientes. Desde el punto de vista informático, el proceso es ligeramente más complejo. En el siguiente diagrama vemos cuál es el flujo básico de la información:
El proceso completo es el siguiente:
1. El paciente es citado en la aplicación RIS.
2. A cada uno de los estudios que se le vayan a realizar al paciente se le asigna un número único llamado "Accession Number". Éste será el dato que conseguirá el enlace entre el RIS y el PACS.
3. Las citas generadas, ya sea en el momento o con algún proceso programado, se envían utilizando mensajería HL7 a la Lista de Trabajo.
4. Al recibir las citas, la lista de trabajo almacenará esa información en su estructura de datos para su posterior consulta. Los datos normales a recibir en un mensaje de cita son:
- Accession Number
- Nombre del Paciente
- Prueba a realizar
- Sala donde se realizará
- Fecha del estudio
- Hora del estudio
- NHC (Número de Historia Clínica)
- Unidad Peticionaria
- Médico Solicitante
5. Cuando el técnico de rayos quiera la información de los pacientes que tiene citados para el día, realizará una petición FIND de Worklist.
6. La Lista de Trabajo devolverá aquellos datos correspondientes a la máquina que realizó la petición. Al realizar la petición, la modalidad dice quién es o para quién pregunta los pacientes. La Lista de Trabajo debe ser capaz de asociar salas con modalidades para enviar la información correcta.
7. Cuando se le realiza el estudio al paciente, en la cabecera de las imágenes viaja el "Accession Number" que le asignó el RIS. Estas imágenes se envían al PACS que almacena esa información.
Finalmente, hemos conseguido que el PACS tenga almacenado para cada estudio su Accession Number.
Utilidad de la WorkList
Una vez que tenemos implementado un entorno de Lista de Trabajo, obtenemos varias ventajas evidentes y varios inconvenientes asociados. Las ventajas son:
6. La Lista de Trabajo devolverá aquellos datos correspondientes a la máquina que realizó la petición. Al realizar la petición, la modalidad dice quién es o para quién pregunta los pacientes. La Lista de Trabajo debe ser capaz de asociar salas con modalidades para enviar la información correcta.
7. Cuando se le realiza el estudio al paciente, en la cabecera de las imágenes viaja el "Accession Number" que le asignó el RIS. Estas imágenes se envían al PACS que almacena esa información.
Finalmente, hemos conseguido que el PACS tenga almacenado para cada estudio su Accession Number.
Utilidad de la WorkList
Una vez que tenemos implementado un entorno de Lista de Trabajo, obtenemos varias ventajas evidentes y varios inconvenientes asociados. Las ventajas son:
- Al no tener que introducir manualmente los datos de los pacientes en las consolas de las modalidades, se evitan muchos fallos en la información. La información llega directamente del sistema RIS, que vendrá del HIS o de algún sistema corporativo.
- Desde el RIS podremos tener acceso a las imágenes de cada paciente mediante la integración con algún visor dicom. Al tener el Accession Number, se pueden realizar consultas dicom directamente al PACS. Esto permite que el RIS se convierta en fachada del PACS, otorgándole inteligencia.
En cuanto a los inconvenientes:
- Se introduce un elemento más dentro del servicio de rayos que modifica el flujo de trabajo normal del personal. Esto obliga a variar el comportamiento habitual.
- En los pacientes de urgencias, el uso de la Lista de Trabajo suele ser complicado puesto que al tener que generar una cita en el RIS, que se envíe vía HL7 a la Worklist y llegue a la modalidad, el tiempo que se pierde es grande. Existen configuraciones que veremos más adelante que permiten paliar este tiempo.

En este esquema mostramos el flujo normal para la petición de imágenes desde el RIS al PACS.
Consideraciones de Funcionalidad de la Lista de Trabajo
A la hora de implementar una Lista de Trabajo hemos de tener en cuenta los siguientes aspectos y prepararnos para que nuestro sistema pueda responder ante ellos:
- La lista de trabajo debe estar preparada para recibir mensajes de creación, modificación y eliminación de citas.
- El formato de los mensajes HL7 puede variar de un RIS a otro, por lo que el sistema debe estar preparado para ser configurable en este aspecto.
- El RIS no debe saber nada de DICOM y las modalidades nada de Salas. Esta labor de unión la debe hacer la Lista de Trabajo. En este aspecto, debe ser totalmente configurable, sabiendo qué modalidad lleva las citas de qué salas.
- Hay momentos en los que una modalidad se rompe por algún motivo. En estos casos, la lista de trabajo debe ser capaz de mover fácilmente las citas de esa modalidad a otra modalidad.
- La lista de trabajo debe tener un administrador visual que permita al administrador configurar todos estos aspectos, realizar consultas o cualquier otro tipo de acción.
Estas son unas cuantas consideraciones, sin embargo, a la hora de implementar una lista de trabajo se deberá realizar un estudio mucho más profundo de las funcionalidades.
Posibles Arquitecturas de Lista de Trabajo:
Existen varias formas posibles de implementar una Lista de Trabajo, cada cual con sus seguidores y detractores. No hay ninguna mejor que otra, cada una tiene unas características diferentes:
Posibles Arquitecturas de Lista de Trabajo:
Existen varias formas posibles de implementar una Lista de Trabajo, cada cual con sus seguidores y detractores. No hay ninguna mejor que otra, cada una tiene unas características diferentes:
- Lista de Trabajo independiente: se puede implementar como un módulo completamente independiente del RIS y del PACS. De esta manera, la portabilidad y la adaptabilidad es mayor que en las otras soluciones. Sin embargo, hay que implementar mayor cantidad de servicios para obtener los mismos resultados que en los otros (MPPS).
- Lista de Trabajo dentro del RIS: de esta manera nos evitamos la utilización de mensajería HL7 que es siempre muy engorrosa, lenta y poco fiable muchas veces. Las citas se mandan directamente en datasets dicom a las modalidades. Tendremos que implementar MPPS para sabert cuando se han realizado las pruebas. No es reutilizable con otros RIS.
- Lista de Trabajo dentro del PACS: tenemos el problema de la mensajería HL7 pero, al estar dentro del PACS, sabemos cuando se han realizado las pruebas porque recibimos las imágenes.
La Mensajería MPPS y la Lista de Trabajo:
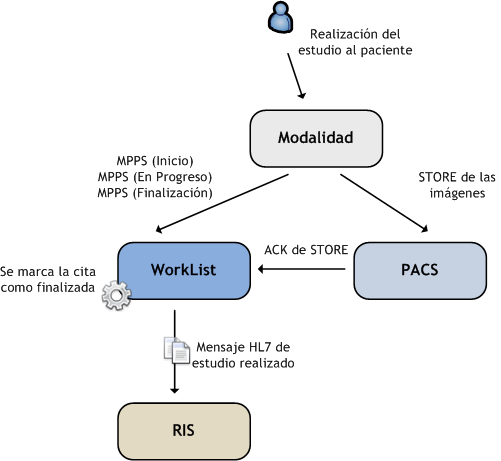
Uno de los grandes problemas de las Listas de Trabajo es que no son capaces de saber cuando se han realizado los estudios y siempre mandan las mismas citas a las modalidades. Para evitar esta situación, el estándar DICOM provee de la mensajería MPPS (Modality Performed Procedure Step) cuya misión es ir informando a una entidad dicom del estado del estudio en curso.
Cuando se le inicia un estudio a un paciente, la modalidad empieza a enviar mensajería a la Lista de Trabajo notificándole de este hecho. Irá enviando información del estado del estudio y cuando lo envíe lo notificará también. En el caso que falle el estudio o se cancele, también se notificará. Por otro lado, el PACS notificará a la Lista de Trabajo cuando se ha recibido la totalidad del estudio. Con esta información, la Lista de Trabajo será capaz de:
- Marcar la cita como realizada (o cancelada si es su caso)
- Enviar un mensaje HL7 al RIS indicándole la finalización del estudio.
Con este intercambio de información, el ciclo de la Lista de Trabajo se cierra.

Con esto cerramos este artículo dedicado a la Lista de Trabajo Dicom o Dicom Modality WorkList. Espero que os haya servido o gustado.
Con esto cerramos este artículo dedicado a la Lista de Trabajo Dicom o Dicom Modality WorkList. Espero que os haya servido o gustado.